Normalized Address Tokenization
Standardizing Address Output for Consistency
Besides the address parsing feature that is available at CSV2GEO during geocoding process, another valuable feature can improve the geocoding process, namely the Normalized Address Tokenization feature. This feature implemented in the CSV2GEO tool helps users to obtain the address in the outcome files into specific sections for each address token, but also combined into one line for the entire address. Moreover, it should be emphasized that if a header is present for each column of the outcome file, then address components are parsed into the correct sections.
The input for an address is usually like “street number, street name, city name, state name, zip code, country”. Taking the example of the California Academy of Sciences in San Francisco, California, we will have the address as “55, Music Concourse Dr, San Francisco, CA 94118, United States”. Whether the address will be typed as groups of address elements, as elements alone or as one line for the entire address, the file outcome after geocoding process will have columns for the coordinates (latitude and longitude), one column for the entire address line and also columns for each element of the address.
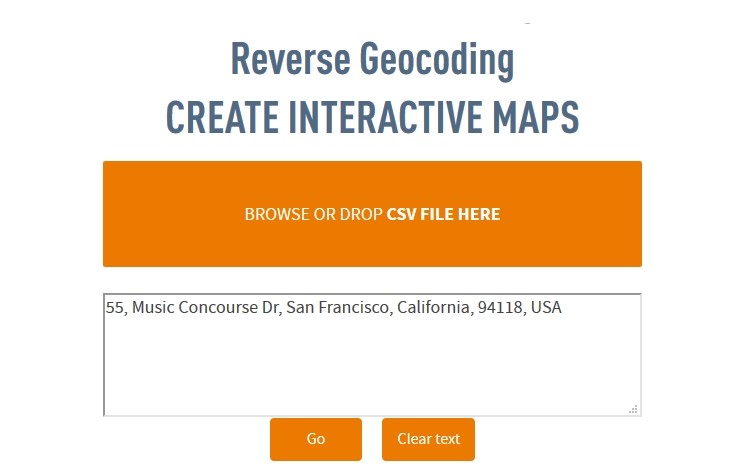

In the above example, the header is missing, but even so each column can be easily identified. Columns B and C are for geographic coordinates, column D is for the entire address, while columns E, F, G, H, I and J includes address tokens like street number, street name, city name, state name, country name and zip postal code. Moreover, in column K of the outcome file obtained from geocoding process the entire address for the California Academy of Sciences in San Francisco, California is written as it can be identified in Google Maps or on the GPS.
Another example is using the CSV file exported from GIS software with a large amount of data having also the header of the table. When the CSV file is opened in the geocoder, you can choose the address token for each column, or you can have one column with all the address elements.
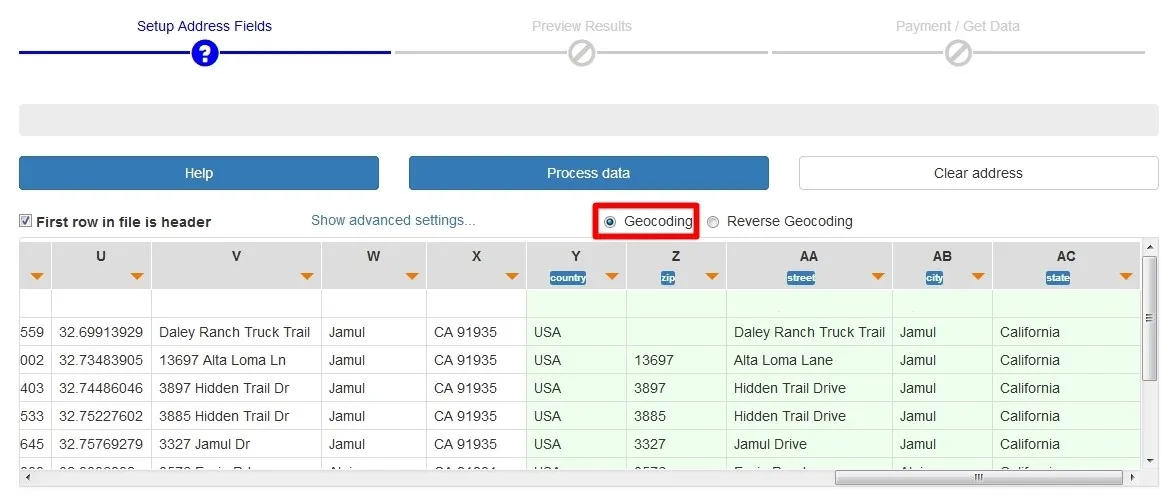
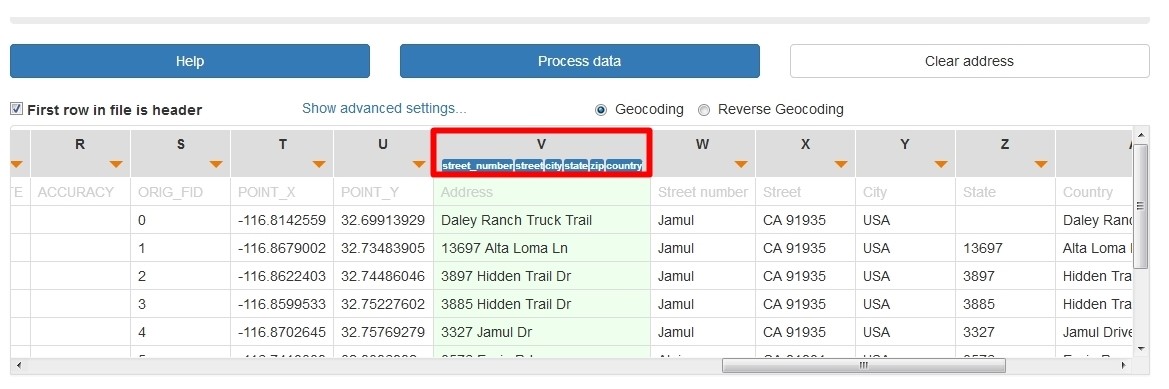
The outcome file will contain the header of the table and the full address in one column (see column V above), then each address element in a different column (street number in column W, street name in column X, city name in column Y, state name in column Z, country name in column AA and zip code in column AB), but also address components separated by commas in a different column (column AC in the image below).
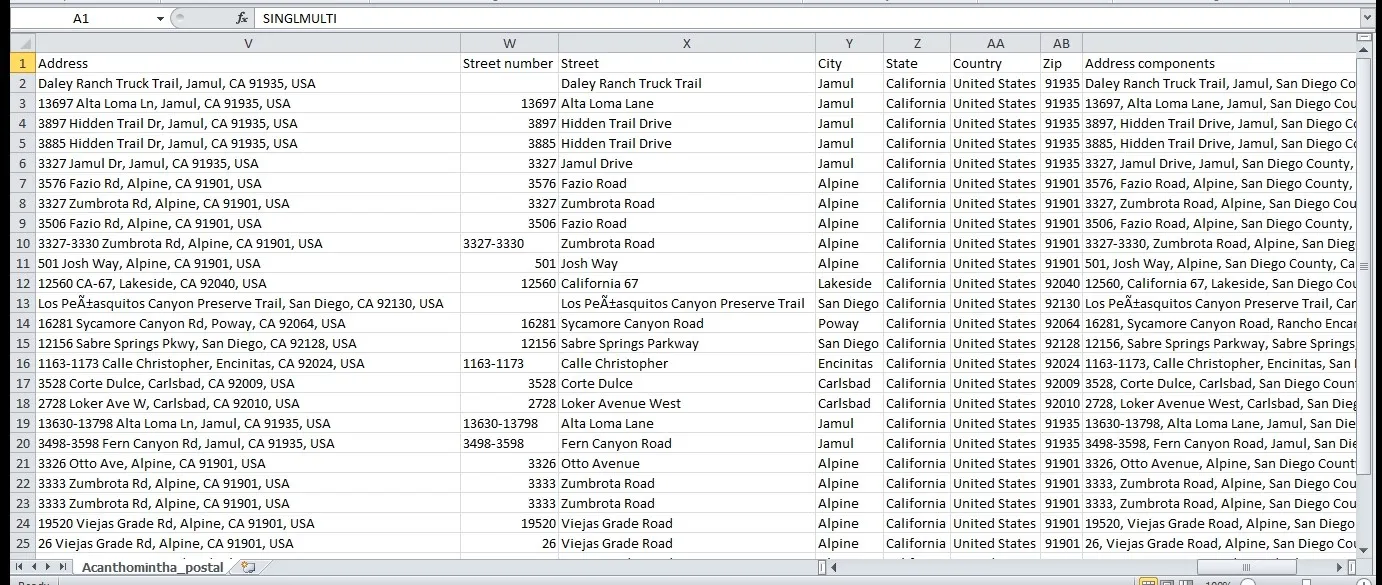
The big advantage of this Normalized Address Tokenization that is implemented in the CSV2GEO tool is given by the fact that the user can obtain both types of information after geocoding process regarding an address: the full line of the address with all the components in one line and a section in the file outcome for each address element. Consequently, the user can have confidence that the systems provide support in order to obtain the correct elements for an address in the final outcome, together with the geographic coordinates.